

Para un lector no especializado, conviene empezar por lo esencial: cuando hoy hablamos de minería y ciencia de datos, NLP (procesamiento del lenguaje natural) o análisis semántico, no hablamos de “magia algorítmica”, sino de métodos para ordenar información muy grande, muy desordenada y muy desigual.
La minería de datos consiste, en términos simples, en buscar patrones repetidos dentro de miles o millones de registros; por ejemplo, qué tipos de descripciones se repiten más en ciertas décadas o regiones. El NLP permite que una máquina trabaje con texto humano: no solo contar palabras, sino comparar significados aproximados entre relatos que no usan exactamente el mismo vocabulario.
Las técnicas de visualización transforman esas comparaciones en mapas o gráficos que hacen visibles estructuras ocultas. Y el análisis estadístico ayuda a responder una pregunta básica pero decisiva: lo que vemos, ¿es realmente un patrón o puede ser azar, sesgo de fuente o efecto de cómo se registró el dato?
Planteado de otra forma, la pregunta clave es: ¿cómo se puede analizar matemáticamente el texto? El primer paso es convertir cada relato en números sin perder del todo su significado. Ahí entran los embeddings: representaciones vectoriales del texto, es decir, listas de valores que colocan cada testimonio en un espacio matemático donde relatos parecidos quedan cerca y relatos muy distintos quedan lejos. A partir de ese espacio vectorial ya se puede aplicar estadística, medir distancias, detectar densidades, buscar outliers (valores atípicos o datos que se alejan mucho del resto) o proyectar la estructura en dos o tres dimensiones para inspeccionarla visualmente. No se trata de reemplazar la lectura humana, sino de darle una escala que la lectura manual no puede alcanzar cuando el corpus tiene decenas o cientos de miles de casos.
Esa capa matemática se vuelve realmente operativa cuando se automatiza sobre bases de datos SQL con Python. En la práctica, Python permite consultar de forma sistemática tablas en SQLite u otros motores relacionales, limpiar y transformar campos, ejecutar análisis repetibles y dejar trazabilidad de cada paso en scripts versionados.
Con las mismas librerías se pueden generar visualizaciones estáticas y dinámicas —series temporales, mapas de densidad, distribuciones, proyecciones UMAP y animaciones 3D— de modo que el flujo completo quede integrado en un único entorno reproducible: extracción desde SQL, análisis numérico y comunicación visual de resultados.
Convertir los documentos en datos computables
El corazón de este enfoque está antes de los modelos sofisticados. Antes de “analizar”, hay que rescatar y preparar el material. Muchos archivos históricos no nacieron como bases de datos, sino como microfilms, PDFs escaneados, listados en HTML antiguo o formularios administrativos con texto irregular. Por eso, la primera fase es arqueológica (fig. 1): extraer texto con OCR (reconocimiento ópticos de caracteres), corregir artefactos (errores), normalizar fechas y ubicaciones, y construir una estructura común que preserve el origen de cada registro.
En la práctica, esto significa pasar del documento aislado al dato trazable, sin borrar la huella de su procedencia. Solo cuando esa base está saneada, las técnicas posteriores tienen valor científico y no producen ruido elegante.

En mi propio recorrido como investigador, ese ha sido precisamente el trabajo que he llevado a cabo en los últimos meses: convertir archivos heterogéneos en corpus comparables. Empecé por fondos históricos anglosajones, especialmente Project Blue Book, trabajando con materiales del archivo NARA (National Archives and Records Administration) y con un pipeline (cadena de pasos o procesos para llegar a un resultado) que integra extracción, validación, canon de calidad textual y estructuración en SQLite. Ese proceso no fue un trámite técnico, sino una investigación en sí misma: permitió medir qué parte del archivo contiene narrativa realmente útil, qué parte es formulario burocrático y qué parte está dañada de origen. El resultado fue un corpus curado y reproducible, apto para análisis lingüístico y estadístico, en lugar de una colección de documentos difíciles de cruzar entre sí.
En paralelo, fui consolidando un mapa más amplio de fuentes y desclasificaciones internacionales para no limitar el análisis a un solo ecosistema documental. En Estados Unidos, además de NUFORC y repositorios históricos como Blue Book, la infraestructura archivística de NARA para UAP se ha formalizado con nuevas colecciones federales y se ha complementado con la revisión institucional reciente de AARO.
En Europa, la referencia francesa sigue siendo GEIPAN (CNES), que publica casos investigados con clasificación oficial, mientras que en el Reino Unido los fondos desclasificados del Ministry of Defence conservados en The National Archives permiten seguir la evolución de políticas, expedientes y cierre operativo de la oficina OVNI.
En España, el conjunto desclasificado del Ministerio de Defensa en la Biblioteca Virtual de Defensa ofrece una serie excepcional para análisis comparado entre 1962 y 1995. A ello se suma el papel de bases privadas o mixtas de gran volumen, como UFOCAT y MUFON, útiles para ampliar cobertura aunque con regímenes de acceso y curación distintos. Esa cartografía de fuentes, cruzada con documentos de tu propio directorio sobre desclasificaciones británicas y españolas, es la que da contexto real al escalado metodológico del proyecto.
Como inventario operativo de trabajo, hoy pueden listarse las siguientes bases de datos y procesos de desclasificación accesibles online. En bases de datos civiles y académicas destacan:
- NUFORC (repositorio abierto de reportes ciudadanos en curso),
- UFOCAT/CUFOS (catálogo histórico de gran escala con estructura codificada),
- MUFON CMS (base privada con acceso por niveles y condiciones de uso),
- GEIPAN/CNES en Francia (casuística oficial con clasificación pública), y
- UFOSINT como capa unificada multi-fuente para consulta analítica.
En desclasificación institucional, los núcleos más relevantes incluyen NARA en Estados Unidos (fondos Blue Book y colecciones UAP federales), el paquete histórico revisado por AARO en su informe de 2024, The National Archives del Reino Unido con los expedientes del MOD liberados por tramos y cierre de la oficina OVNI en 2009, y la Biblioteca Virtual de Defensa en España con los expedientes OVNI desclasificados del Ministerio de Defensa (1962-1995).
A partir de ahí, fui ampliando escala y alcance. En paralelo al trabajo con Blue Book, incorporé bases mayores como UFOCAT en versión limpia y deduplicada, y más tarde el ecosistema integrado de UFOSINT, que reúne UFOCAT, NUFORC, MUFON, UPDB y UFO-search en una capa analítica común. Ese salto de escala exigió reforzar métodos de deduplicación, control de consistencia y comparación entre catálogos con culturas documentales distintas.
La pregunta ya no era solo “qué dice cada caso”, sino “qué estructura narrativa emerge cuando cientos de miles de testimonios se leen a la vez”. En ese contexto, el uso de embeddings semánticos, reducción dimensional (UMAP), detección de anomalías y análisis topológico me permitió contrastar hipótesis sobre continuidad del espacio narrativo, estabilidad temporal y residuos anómalos, evitando dar por sentado que toda agrupación algorítmica equivale a categorías “naturales”.
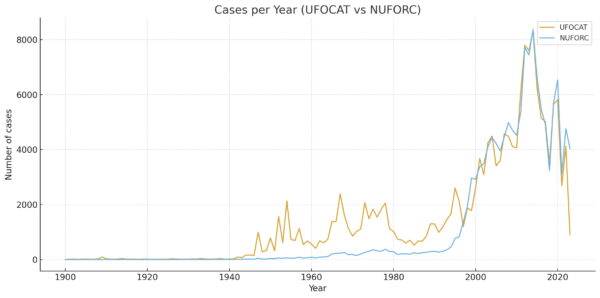
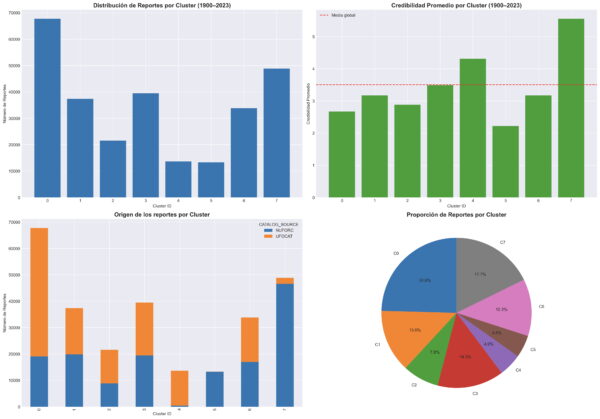
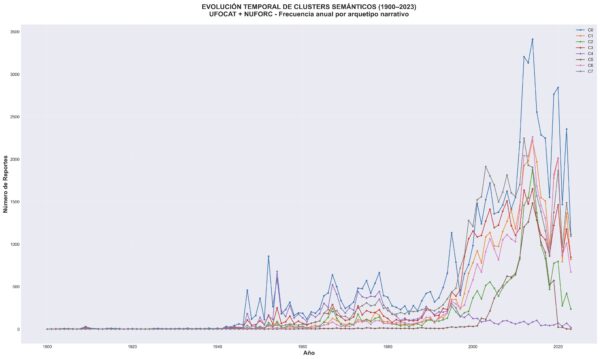
Sin embargo, el tramo más personal y representativo de mi trabajo ha sido el corpus español de expedientes OVNI desclasificados del Ministerio de Defensa (1962-1995). Allí el reto no era solo analítico, sino de recuperación documental fina: expedientes escaneados con calidad dispar, formularios militares, lenguaje técnico, topónimos y siglas institucionales. El trabajo combinó OCR de alta exigencia, limpieza iterativa con diccionario de dominio, extracción de campos, base relacional auditable y análisis semántico de conjunto. Ese proceso permitió pasar de la lectura caso a caso a una lectura estructural del archivo completo: medir densidad narrativa, detectar sesgos de redacción institucional, mapear comunidades semánticas y localizar casos verdaderamente atípicos sin depender solo de intuición cualitativa.

Ese resultado español fue, en mi trayectoria, una prueba de concepto y un punto de inflexión. Demostró que un archivo histórico nacional, aparentemente pequeño frente a las grandes bases internacionales, podía tratarse con el mismo rigor metodológico que un corpus masivo. Y, sobre todo, mostró que el método escalaba: lo aprendido al trabajar con esos expedientes se pudo proyectar hacia conjuntos mucho más amplios, donde las preguntas sobre estructura semántica, evolución temporal y comparabilidad entre fuentes adquieren otra dimensión.
En ese sentido, el camino fue exactamente el inverso al habitual: no empecé por el “big data” para luego bajar al detalle, sino por la recuperación crítica del detalle para poder subir con garantías a la gran escala.
Como prueba de concepto temprana de este enfoque, publiqué también un case study específico sobre el Washington Flap de 1952 usando UFOCAT 2023, donde mostré cómo la conversión de Access a SQLite, la explotación SQL y el análisis automatizado con Python permiten validar patrones temporales, geográficos y fenomenológicos en un episodio histórico concreto antes de escalar el método a corpus mucho más grandes.
La visualización ha sido una parte central de ese proceso, no como adorno sino como instrumento de verificación. Las figuras 2, 3 y 4 permiten hacerse una idea del tipo de visualizaciones que se pueden llevar a cabo con Python para su análisis científico. En la misma línea, se pueden generar animaciones que documentan exploraciones dinámicas del espacio semántico construidas a partir de embeddings textuales, proyección tridimensional y renderizado interactivo. Estas piezas no “demuestran” por sí solas una tesis, pero sí cumplen una función científica concreta: volver observable, discutible y falsable la geometría narrativa del corpus.
En esta misma dirección metodológica, recientemente he sido admitido en la Scientific Coalition for UAP Studies (SCU), donde existe un grupo de trabajo centrado en NLP aplicado al estudio UAP. Este paso refuerza una convicción que atraviesa todo mi trabajo: cuando se aplican técnicas computacionales con trazabilidad, control de calidad y criterios reproducibles,es posible hacer ciencia objetiva sin imponer explicaciones previas. Ese enfoque no apriorístico permite caracterizar el fenómeno como hecho complejo desde tres planos complementarios: el antropológico (cómo narran los testigos), el cultural (cómo cambian los marcos de interpretación) y el científico (qué patrones estables emergen en los datos bajo análisis riguroso).
El estigma en las revistas científicas revisadas por pares
También conviene decirlo con claridad: existe una fricción editorial real cuando estos trabajos intentan entrar en revistas revisadas por pares. No siempre se discute solo la calidad metodológica; con frecuencia pesa un estigma previo asociado al tema OVNI/UAP que desplaza el foco desde los datos hacia la etiqueta del objeto de estudio. Ese handicap no se resuelve con retórica, sino con estándares aún más altos de transparencia, reproducibilidad y precisión conceptual. Pero, al mismo tiempo, la comunidad científica necesita revisar sus propios reflejos culturales: estudiar seriamente un corpus histórico de testimonios no implica adoptar una conclusión extraordinaria, sino aplicar herramientas ordinarias de ciencia a un fenómeno social y documental extraordinariamente persistente. Normalizar ese marco de trabajo, sin sensacionalismo y sin prejuicio apriorístico, es hoy una tarea tan científica como técnica.
En esa lógica de blindaje metodológico, una exigencia central es comparar los datasets textuales UAP con corpus externos no-UAP —por ejemplo AG News, 20 Newsgroups, Reuters, IMDB, SST, DBpedia, Yahoo Answers o arXiv/PubMed— como control de validación, para distinguir qué parte de la geometría observada pertenece al fenómeno narrativo y qué parte es artefacto del tamaño, el dominio o el régimen documental; justamente ese contraste sistemático es el que he desarrollado en estos trabajos que a la fecha de este artículo han sido enviados para su publicación a diversas revistas científicas.
El análisis computacional eleva la conversación
Si tuviera que resumir qué aportan hoy estas técnicas a la investigación histórica OVNI/UAP, lo diría así: no sustituyen el juicio experto ni resuelven automáticamente la naturaleza del fenómeno, pero sí elevan el estándar de la conversación. Obligan a explicitar fuentes, sesgos, límites y reproducibilidad. Permiten distinguir mejor entre ausencia de dato y dato ambiguo, entre patrón robusto y efecto de registro, entre narrativa singular y estructura de conjunto. En mi experiencia, ese cambio de método es el verdadero avance: convertir archivos heredados, dispersos y desiguales en infraestructura analítica viva, capaz de generar conocimiento nuevo sin perder memoria documental.
Como marco empírico de estos resultados, hoy existen cientos de miles de notificaciones de avistamientos acumuladas en bases de datos durante más de setenta años, lo que permite plantear con fundamento la hipótesis de un fenómeno persistente todavía pobremente caracterizado a nivel científico.
Conclusiones científicas preliminares sobre las bases de datos UAP
En este momento de mi investigación se puede concluir:
- Las bases UAP no constituyen un censo exhaustivo del fenómeno, sino una muestra observacional con sesgos de notificación, cobertura geográfica y régimen institucional.
- La heterogeneidad entre catálogos (civiles, militares, periodísticos y mixtos) introduce efectos de medición que impiden comparar frecuencias brutas sin normalización previa.
- La calidad de metadatos (fecha, localización, fuente primaria y cadena de custodia documental) determina la potencia inferencial más que el volumen total de casos.
- La deduplicación interbase revela que una fracción no trivial de “nuevos” casos son variantes narrativas del mismo evento, con impacto directo en estimaciones de incidencia.
- El análisis temporal muestra no estacionariedad: los picos de reporte responden en parte a cambios sociomediáticos y administrativos, no solo a variación del fenómeno observado.
- La estructura textual de los reportes presenta clústeres semánticos estables, pero sus fronteras dependen del protocolo de codificación y del dominio lingüístico de cada fuente. La narrativa global se asemeja a un corpus continuo manifold similar al del folklore, pero con persistencia de motivos culturales.
- Los outliers semánticos y estadísticos existen (casos de elevada extrañeza), pero su detección robusta exige control de calidad documental para distinguir anomalía fenomenológica de ruido de transcripción.
- La comparabilidad internacional mejora al mapear ontologías comunes de variables, aunque persisten pérdidas de información por diferencias idiomáticas y taxonómicas.
- La validación con corpus externos de texto no-UAP confirma que parte de la geometría del embedding es específica del dominio UAP y parte corresponde a propiedades generales del lenguaje narrativo.
- El resultado más sólido no es una conclusión ontológica sobre el fenómeno, sino una mejora objetiva de capacidad descriptiva, trazabilidad y falsabilidad en el estudio de archivos UAP.
Referencias
- Mike Entropic. (2026, 27 de febrero). Minería de datos y análisis textual de los expedientes OVNI desclasificados del Ministerio de Defensa de España (1962-1995). https://mikeentropic.wordpress.com/2026/02/27/mineria-de-datos-y-analisis-textual-de-los-expedientes-ovni-desclasificados-del-ministerio-de-defensa-de-espana-1962-1995/
- Mike Entropic. (2026, 13 de abril). Project Blue Book: la historia completa del programa secreto con el que el Ejército del Aire de EE.UU. investigó los ovnis durante 22 años. https://mikeentropic.wordpress.com/2026/04/13/project-blue-book-la-historia-completa-del-programa-secreto-con-el-que-el-ejercito-del-aire-de-ee-uu-investigo-los-ovnis-durante-22-anos/
- Mike Entropic. (2025, 16 de noviembre). Análisis cuantitativo y cualitativo por data science del Washington Flap de 1952 basado en la base de datos UFOCAT 2023. https://mikeentropic.wordpress.com/2025/11/16/analisis-cuantitativo-y-cualitativo-por-data-science-del-washington-flap-de-1952-basado-en-la-base-de-datos-ufocat-2023/
Algunas bases de datos y repositorios mencionados en el artículo:
- UFOSINT (Observatory): https://ufosint.com/#/observatory?date_from=1900&date_to=2026
- NUFORC (National UFO Reporting Center): https://nuforc.org
- UFOCAT / CUFOS: https://cufos.org
- MUFON (CMS): https://www.mufon.com
- GEIPAN (CNES, Francia): https://www.cnes-geipan.fr
- NARA UAP Records Collection (EE.UU.): https://www.archives.gov/research/topics/uaps
- AARO (All-domain Anomaly Resolution Office): https://www.aaro.mil
- The National Archives (Reino Unido, archivos MOD/UFO): https://www.nationalarchives.gov.uk
- Biblioteca Virtual de Defensa (España, expedientes OVNI desclasificados): https://bibliotecavirtual.defensa.gob.es
- UFOSINT Explorer. (2026). Observatory (1900-2026): https://ufosint.com










{kind=link}
¡Vaya curre! Siempre se ha investigado y se seguirá con ello. Cuando el río suena agua lleva. En las expediciones al espacio hay algo más que turismo y quizá no seamos los únicos visitantes de la luna. Tiene que haber más documentación oculta que no conviene que salga a la luz por los intereses que sean. En todo caso has hecho es muy clarificador para los que, aunque nos atraiga, somos profanos en el tema.